Using AWS Database Migration Service to replicate data from MySQL to Redshift
AWS’s Database Migration Service (DMS) is often misunderstood as a service that can only migrate your data to the cloud. But the service could be very useful for replicating data between the two datastores within the cloud as well. In our case, both of our datastores – RDS (MySQL) and Redshift were already in the cloud. The MySQL database is our primary OLTP database and many of our employees login to an internal application to modify data within this database. This database contains all of our dimension tables. Our reporting dashboard connects with our data warehouse built on Redshift. This database contains all of our fact tables. In order to run the reports accurately it’s important that all the modifications done to the dimension tables in MySQL are transferred to Redshift in timely manner.
Before using DMS, we had a Groovy script that was transferring data from MySQL to Redshift every night. This script would simply read all the rows from a MySQL table, delete all the rows in Redshift table and insert all the rows in the Redshift table. This would take down our reporting dashboard for 30 minutes every night. But we started opening offices worldwide (London and Sydney) and this wasn’t an option anymore. Furthermore, some users were demanding that changes to some tables are reflected in the warehouse immediately. Our script was simply not capable of replicating changes in real time.
There are many options available in the market for such a replication – FiveTran, Alooma, Informatica. There is even an open source solution – Tungsten. But we were always looking for a managed solution. When we learned that AWS offered a similar solution it was a no brainer. Our security conscious ops team didn’t like the idea of sending sensitive data to an outside company server and bringing back in again. Furthermore it would require no approvals from anybody to use a one more AWS service. DMS also have a good API which makes it easy to use.
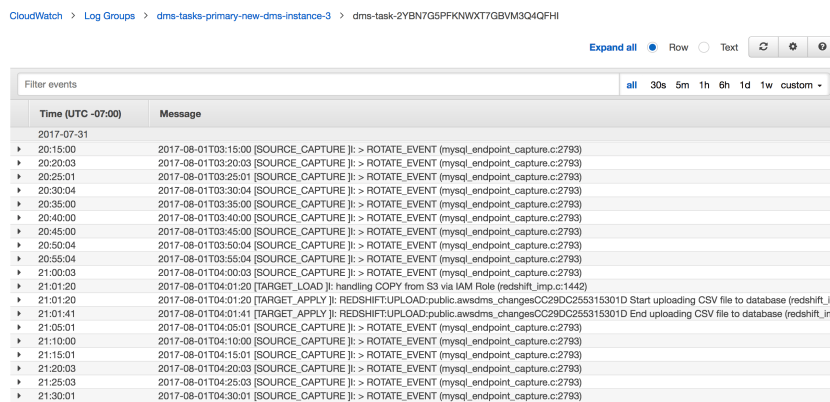
Once decided, the implementation was fairly easy. DMS has concept of replication tasks and replication instances. You can define source endpoints (MySQL) and target endpoint (Redshift). Creating replication tasks to replicate data from one table to another table was few clicks in the console. You can place one or more replication tasks on one replication instance. You need to enable ROW level binlog in MySQL and create the replications tasks. DMS will watch the bin log for any changes and as soon as the changes appear in binlog, DMS will replicate it to the target tables. You can learn more about varous DMS replication related concepts at http://docs.aws.amazon.com/dms/latest/userguide/CHAP_GettingStarted.html
The motive behind this post is to share the knowledge we gained while implementing DMS at GumGum. Here are some of the implementation issues we faced:
- If you don’t specify primary keys on the target tables (Redshift tables in our case), your replication latency may increase. Redshift doesn’t obey the primary keys and hence sometimes you may be tempted not to define them in the schema. But that would be bad for DMS. Here is what they say in documentation – “If you haven’t created primary or unique keys on the target tables, then AWS DMS must do a full table scan for each update, which can significantly impact performance”.
- DMS doesn’t support Enum fields in MySQL. It’s not a big issue since MySQL Enums can be easily replaced by check constraints or foreign keys with lookup tables.
Here are some of the issues we faced in production:
- Be careful about the source database reboot. Make sure that all replication tasks are completely stopped before you reboot the database. Otherwise replication tasks may fail.
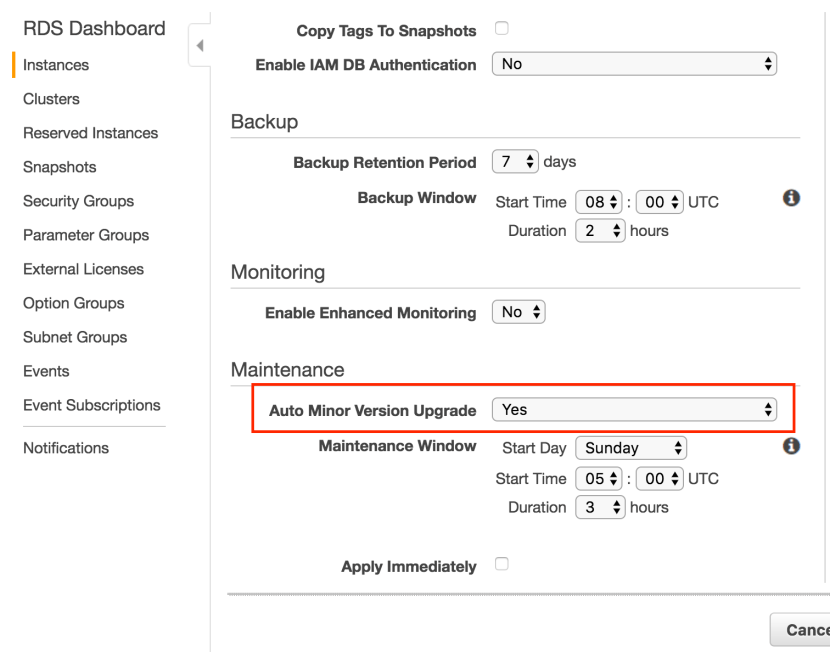
- Be very careful about RDS’s Auto Minor Version Upgrade feature. This checkbox if checked, will upgrade database in the maintenance window and reboot the database. Once one such update broke mysql bin log and all of our replication tasks stopped working. The only way we were able to get it working is by upgrading our MySQL to version 5.7.X!
- Beware that outages in other AWS services can break DMS replication. Remember the great Amazon S3 outage earlier this year? If S3 is not available, you cannot use COPY command in Redshift and hence replication breaks!
Here are some of the best practices we recommend based on our experiences:
- Create one replication task per table to be replicated. You can actually add many tables to a single replication task. But we definitely don’t recommend that. Creating one task per one table will ensure that when a replication task fails, only one table’s replication is affected.
- Write a script to perform usual maintenance tasks such as reload a table, add new replication task, move a replication task from one instance to another etc. Creating a simple script will ensure that every team member will use DMS in a consistent manner. Furthermore, we also play with target table permissions when we are performing these tasks. Having a script makes it easy to add additional steps integrate with DMS tasks.
- Even though DMS can create your target tables, it’s recommended that you create target tables yourself manually. Sometimes data types don’t get converted properly and default values don’t get set. Sometimes you may want to choose a different data type than DMS.
- Write a script to measure drift of your source and target tables. In our case the tables replicating were fairly small tables. The biggest table had 10 to 15,000 rows. Even the biggest table had only 5 mb of data. We wrote a script to query a mysql table, query the corresponding Redshift table and compare the rows column by column every couple of hours. This has helped us immensely to detect replication related problems. It can also tell you the extent of the drift between your source table and target tables. Running such a script frequently can also detect your latency issues. Especially in the initial period when you are working out kinks such as script can be very helpful.
What do you do when replication breaks?
In 90% cases, simply restarting a replication task works! In cases where you can’t restart the task, you can simply reload the table and start replication from scratch. We take out permissions for our dashboard to access the target table in Redshift and then reload the table using DMS. Taking out permission ensures that while DMS is reloading a table, if a report tries to access the table, it errors out. It’s better to error out than show a report with wrong data. Having a script to reload table comes handy in such cases. Since these tables are fairly small, reloading won’t last more take 2 to 3 minutes. And certainly, don’t forget to look at the DMS log to see the root cause of the problem. DMS’s replication log is usually very helpful.